1. 分布式服务框架Dubbo
1.1. Dubbo原理
1.2. Dubbo支持哪些序列化协议
- Dubbo支持哪些通信协议
- dubbo://协议
- 默认协议,单一长连接,进行的NIO异步通信,基于hessian作为序列化协议
- 特性,传输数据量小(每次100k以下);并发量高,适用多个消费者的情况
- rmi://协议
- 采用JDK标准的Java.rmi.*实现
- 特性,多个短链接,适合消费者和提供者差不多的情况,适用文件传输
- hessian://协议
- http通信,采用servlet暴露服务,基于hessian序列化协议
- 多个短链接,适用于提供者数量多的情况,适用文件传输
- http://协议
- 基于http表单的远程通用协议,走单表序列化
- thrift://协议
- 在原生协议的基础上添加了一些额外的头信息,如service name,magic number等
- webservice://协议
- 基于apache cxf的fronted-simple和transports-http实现,SOA文本序列化
- memcached://协议
- RPC协议
- redis://协议
- RPC协议
- rest://协议
- 实现REST调用支持
- grpc://协议
- 适用HTTP/2通信,想利用Stream、反压、Reactive变成能力的开发者适用
- dubbo://协议
- 支持的序列化协议
支持hessian,java二进制序列化,SOAP文本序列化,json多种序列化协议
1.3. Dubbo的负载均衡策略和集群容错策略
4中负载均衡策略,6种集群容错策略
1.3.1. Dubbo的负载均衡策略
RandomLoadBalance,默认策略,随机调用;可以对provider设置不同的权重,按照权重来负载均衡。
算法思想:假设有一组服务器servers=[A,B,C],对应权重为weights=[5,3,2],总和为10.把权重平铺在一纬坐标值上,则[0,5]服务器A,[5,8]服务器B,[8,10] 属于服务器C.随机数生成器生成一个范围在[0,10]之间的随机数,然后计算会落在哪个区间的服务器,坐标轴上区间范围大的,随机数生成的数字就有更大概率落到此区间
RoundRobinLoadBalance,均匀分发
算法思想:均匀地将流量打到各个机器上,但是如果各个机器性能不同,容易导致性能差的机器负载过高。所以需要调整权重,让性能差的机器承载权重小一些,流量少一些
LeastActiveLoadBalance,最小活跃数负载均衡,活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多请求,此时请求会优先分配给该服务提供者
算法思想:每个provider对应一个活跃数active。初识情况,provider的active均为0.每收到一个请求,对应的provider的active会加1,处理完请求后,active会减1.所以,如果provider性能好,处理请求的效率就越高,active下降的越快。也引入了权重值,所以此算法是基于加权最小活跃数算法实现
ConsistenHashLoadBalance,一致性hash
算法思想:一致性Hash算法,相同参数请求一定分发到一个provider去。如果需要的不是随机负载均衡策略,要一类请求都到一个节点,那就走一致性Hash策略
1.3.2. 集群容错策略
- Failover Cluster模式,默认这个,失败自动切换,自动重试其它机器,常见于读操作
- Failfast Cluster模式,一次调用失败就立即失败,常见幂等性的写操作,如新增一条记录
- Failsafe Cluster模式,出现异常时忽略,用于不重要的接口调用,如记录日志
- Failback Cluster模式,失败了后台自动记录请求,然后定时重发,适合写消息队列失败
- Forking Cluster模式,并行调用多个provider,只要一个成功就立即返回。用于实时性要求较高的读操作,但是会浪费更多服务资源
- Broadcast Cluster模式,逐个调用所有的provider,任何一个出错则报错。用于通知所有提供者更新缓存或日志等本地资源信息
1.4. Dubbo的SPI思想
service provider interface
1.4.1. spi概念
一个接口,有三个实现类,在系统运行时这个接口该选择哪个实现类?就需要根据指定的配置或者是默认的配置,找对应的实现类加载进来,用这个实现类的实例对象。插件扩展的场景
1.4.2. java spi思想的体现
经典思想JDBC。java定义了一套jdbc的接口,并没有提供jdbc的实现类,所以可以使用mysql-jdbc-connector.jar引入或者oracle-jdbc-connector.jar
1.4.3. dubbo的spi思想
Protocol 接口,在系统运行的时候,,dubbo 会判断一下应该选用这个 Protocol 接口的哪个实现类来实例化对象来使用,它会去找一个你配置的 Protocol,将你配置的 Protocol 实现类,加载到 jvm 中来,然后实例化对象,就用你的那个 Protocol 实现类就可以了
Protocol protocol=ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol http=com.alibaba.dubbo.rpc.protocol.http.HttpProtocol hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol
1.5. 基于Dubbo的服务治理
服务治理:调用链路自动生成;服务访问压力以及时长统计
1.5.1. 服务降级
接口+Mock后缀,如:
<dubbo:service interface="com.zhss.service.HelloService" ref="helloServiceImpl" timeout="10000"/><bean
id="helloServiceImpl" class="com.zhss.service.HelloServiceImpl"/>
降级逻辑 public class HelloServiceMock implements HelloService { public void sayHello() { // 降级逻辑 }}
1.5.2. 失败重试/超时重试
<dubbo:reference id="xxxx" interface="xx" check="true" async="false" retries="3" timeout="2000"/>
timeOut:一般设置为200ms,retries:设置重试次数
1.6. 分布式服务的幂等性如何设计
场景:假如有个服务部署在5台机器上,有个接口是付款接口,用户在前端操作,一个订单不小心发起了两次支付请求,然后分散在了这个服务部署的不同机器上
1.6.1. 如何保证幂等性?
- 对于每个请求必须有一个唯一的标识,如:订单支付请求,订单id需要唯一
- 每次处理完请求后,必须有一个记录标识这个请求处理过了,如在mysql中记录个状态
- 每次接收请求需要进行判断,判断之前是否处理过。唯一键约束
1.7. 分布式服务接口请求顺序如何保证
场景:服务A调用服务B,先插入再删除。结果俩请求过去,落在不同机器上,可能因为插入请求因为某些原因执行慢了,导致删除请求先执行了
1.7.1. 如何保证顺序
- 尽量合并成一个操作,避免此问题产生
可以使用Dubbo的一致性hash负载均衡策略,将比如某一个订单id对应的请求都分发到某个机器上,然后可以将某个订单id对应的请求放到一个内存队列中,强制排队,来确保顺序性
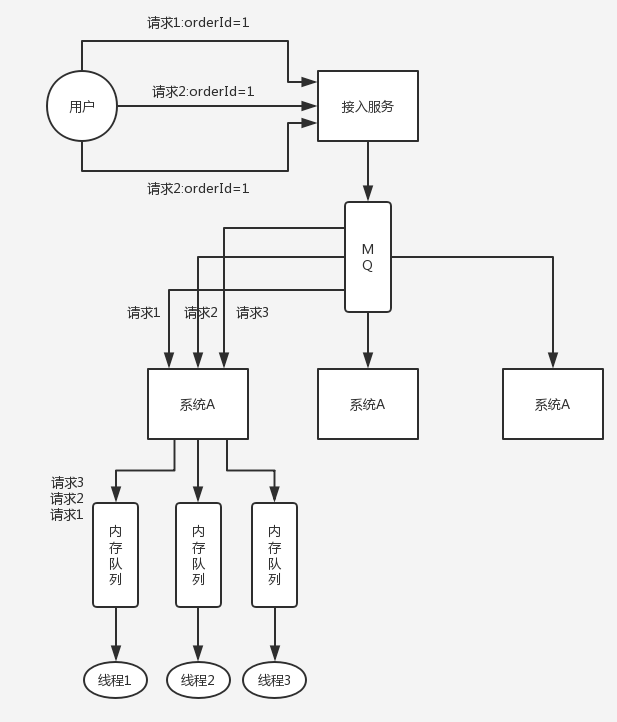
1.8. 自己设计一个类似Dubbo的RPC框架
- 注册中心服务注册,可以用zk
- 消费者需要去注册中心拿对应服务信息,而且每个服务可能存在于多台机器上
- 发起一次请求,基于动态代理,面向接口获取到一个动态代理,然后这个代理找到服务对应的机器地址
- 使用简单的负载均衡策略确定向哪个机器发送请求
- 使用netty,nio方式,使用hessian序列化协议
- 服务器侧,针对自己的服务生成一个动态代理,监听某个网络端口
1.9. CAP理论
CAP,Consistency一致性,Availability可用性,Partition tolerance分区容错性
- C:所有节点访问同一份最新的数据副本
- A:每次请求都能获取到正常响应,不保证获取的数据为最新数据
- P:分区相当于对通信的时限要求。系统不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择
常用的CAP框架
- eureka(AP):保证可用,实现最终一致性。使用内置轮询负载均衡器去注册,有一个检测间隔时间,如果在一定时间没有收到心跳,才会移除该节点注册信息。eurekaAP的特性和请求间隔同步机制
- zookeeper(CP):强一致性。在选举leader时会停止服务,只有成功选举后才能提供服务
1.10. 分布式事务
这里列举五种事务方案,具体得看本身业务
1.10.1. 两阶段提交方案/XA方案
有一个事务管理器,负责协调多个数据库的事务,事务管理器先问各个数据库你准备好了吗?如果都回复ok,就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不ok,那么就回滚
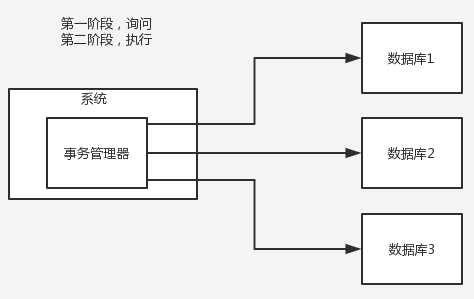
- 场景应用:常见单应用实例内跨多个库的分布式场景
(缺点是严重依赖数据库层面来搞定复杂的事务,效率很低,不适合高并发场景)
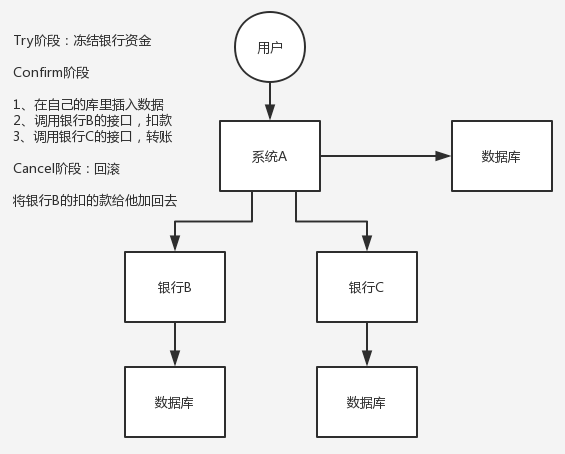
1.10.2. TCC方案,try,confirm,cancel(金融场景选择方案)
- try阶段,各个服务的资源做检测以及对资源进行锁定或者预留
- confirm阶段,在各个服务中执行实际的操作
- cancel阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,已经执行成功的业务逻辑回滚
对于一致性要求高、短流程、并发高的场景,会考虑TCC方案
1.10.3. saga方案(长事务)
业务流程中每个参与者都提交本地事务,若某一个参与者失败,则补偿前面已经成功的参与者
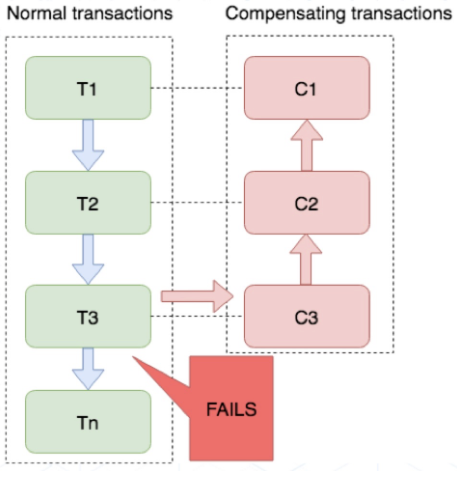
- 适用场景:业务流程长、业务流程多;参与者包含其它公司或遗留系统服务,无法提供TCC模式要求的三个接口
- 优势:
- 一阶段提交本地事务,无锁高性能
- 参与者可异步,高吞吐
- 补偿服务易于实现,因为一个更新操作的反向操作易于理解
- 缺点:不保证事务的隔离性
1.10.4. 可靠消息最终一致性方案
直接使用MQ来实现事务,如阿里的RocketMQ支持事务
1.10.5. 最大努力通知方案
- A本地事务执行完成后,发送消息到MQ
- 有专门消费MQ的最大努力通知服务,这个服务消费MQ然后写入数据库中记录,或者放入内存队列,接着调用系统B接口
- B执行成功就ok,要是执行失败,最大努力通知服务就定时尝试重新调用系统B,反复N次,最后还是不行就放弃
1.10.6. 本地消息表
严重依赖数据库的消息来管理事务,高并发场景并不适合
- A系统在自己本地一个事务里操作同时,插入一条数据到消息表
- A系统将这个消息发送到MQ
- B系统收到消息后,在一个事务里,往自己的本地消息表插入一条数据,同时执行其它业务操作,如果消息被处理过了,那此时这个事务回滚,保证不会重复处理消息
- B系统执行成功后,更新自己本地消息表状态以及A系统消息表状态
- B如果处理失败,那不更新消息表状态,此时A系统定时扫描自己的消息表,如果有未处理消息,再次发送到MQ,让B再次处理
- 保证了最终一致性,B失败,A会不断发消息,直至B成功
1.11. 为什么要拆分分布式系统
- 拆分服务,减少代码改动冲突,影响范围变小,开发效率高
- 减少服务发布影响范围,减少代码测试范围
1.11.1. 如何进行拆分
多轮拆分,根据业务性质拆分,如订单系统,商品系统等等
1.11.2. dubbo和服务拆分有什么关系
可以不用dubbo,纯http通信,但是就要考虑负载等问题,所以dubbo其实就是一个rpc框架,本地调用接口,dubbo会代理这个调用请求,跟远程机器网络通信,处理掉负载均衡、服务实例上下线自动感知、超时重试等
1.11.3. zk的一些场景
- 分布式协调,A系统发送了个消息到mq里去,然后B系统消费处理,那B系统消费处理后A如何知道结果?
解决:用ZK实现分布式系统之间的协调 A系统发送后在Zk上对某个节点的值注册个监听器,一旦B处理完就修改ZK那个节点的值,A系统立马就可以收到通知
- 分布式锁
1.12. 基于Hystrix实现高可用
Hystrix让我们在分布式系统中对服务间调用进行控制,加入调用延迟或者依赖故障的容错机制;还提供故障时的fallback降级机制
1.12.1. 有哪些限流算法
- 计数器
控制单位时间内的请求数量。
劣势:设每分钟请求数量60个,每秒处理1个请求,用户在 00:59 发送 60 个请求,在 01:00 发送 60 个请求 此时 2 秒钟有 120 个请求(每秒 60 个请求),远远大于了每秒钟处理数量的阈值。(突刺现象)
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {
/**
* 最大访问数量
*/
private final int limit = 10;
/**
* 访问时间差
*/
private final long timeout = 1000;
/**
* 请求时间
*/
private long time;
/**
* 当前计数器
*/
private AtomicInteger reqCount = new AtomicInteger(0);
public boolean limit() {
long now = System.currentTimeMillis();
if (now < time + timeout) {
//单位时间内
reqCount.addAndGet(1);
return reqCount.get() <= limit;
} else {
//超出单位时间
time = now;
reqCount = new AtomicInteger(0);
return true;
}
}
}
- 滑动窗口
对计数器的一个改进,增加一个时间粒度的度量单位,一分钟分为若干份(如6份,没10秒一份),在每份上设置独立计数器,
- leaky bucket漏桶
规定固定容量的桶,进入的水无法管控数量、速度,但是对于流出的水我们可以控制速度
劣势:无法应对短时间突发流量(桶满了就丢弃)
public class LeakBucket {
/**
* 时间
*/
private long time;
/**
* 总量
*/
private Double total;
/**
* 水流出速度
*/
private Double rate;
/**
* 当前总量
*/
private Double nowSize;
public boolean limit() {
long now = System.currentTimeMillis();
nowSize = Math.max(0, (nowSize - (now - time) * rate));
time = now;
if ((nowSize + 1) < total) {
nowSize++;
return true;
} else {
return false;
}
}
}
- Token Bucket令牌桶
规定固定容量的桶,token 以固定速度往桶内填充, 当桶满时 token 不会被继续放入, 每过来一个请求把 token 从桶中移除, 如果桶中没有 token 不能请求。
可以准备一个队列,用来保存令牌,另外通过一个线程池定期生成令牌放到队列中,每来一个请求,就从队列中获取一个令牌,并继续执行。
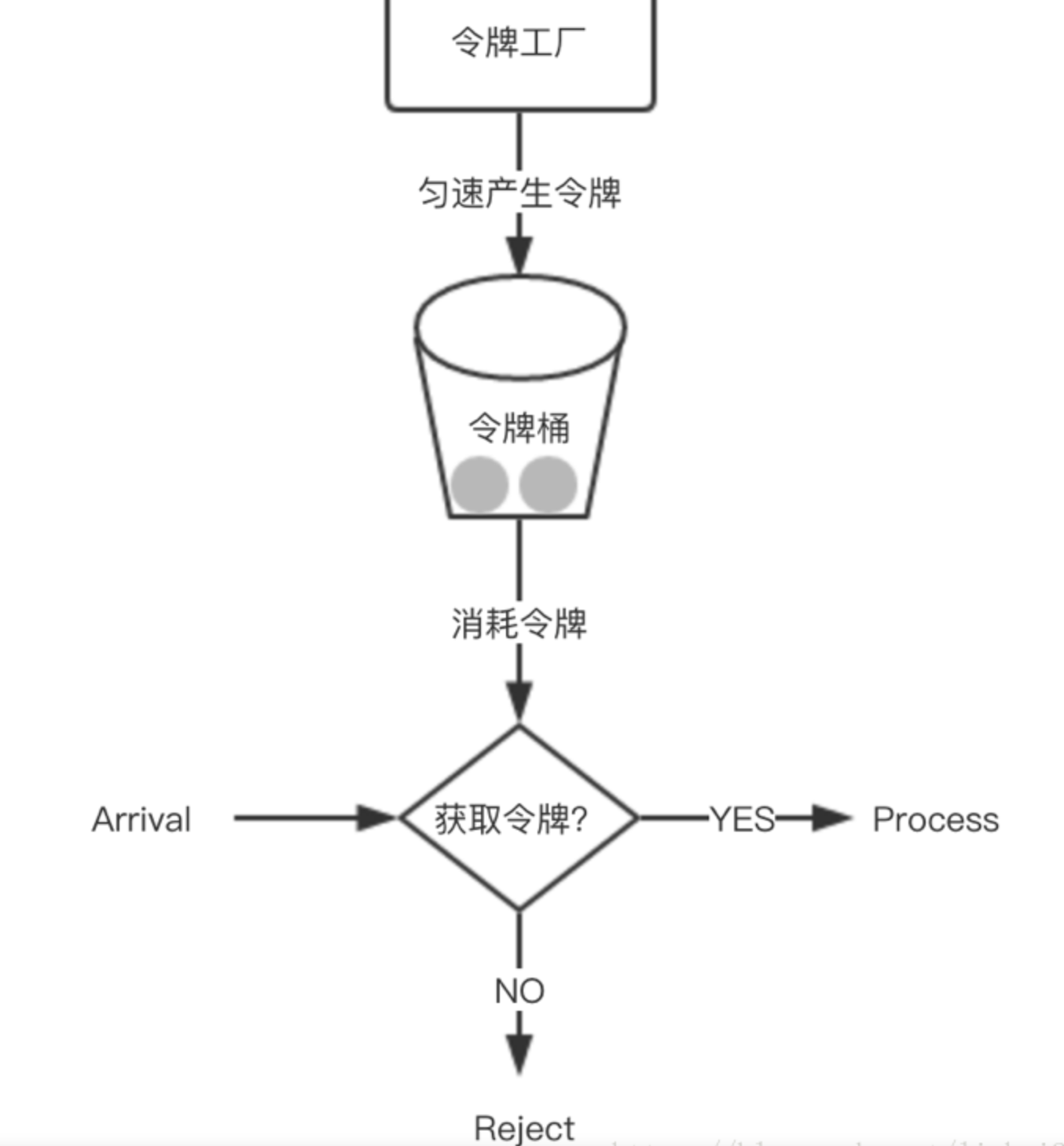
public class TokenBucket {
/**
* 时间
*/
private long time;
/**
* 总量
*/
private Double total;
/**
* 水流出速度
*/
private Double rate;
/**
* 当前总量
*/
private Double nowSize;
public boolean limit() {
long now = System.currentTimeMillis();
nowSize = Math.min(total, (nowSize + (now - time) * rate));
time = now;
if (nowSize < 1) {
//桶里没有token
return false;
} else {
//存在token
nowSize -= 1;
return true;
}
}
}
1.13. Dubbo如何在RPC调用时异步转同步?
TCP协议本身异步,发送完RPC请求后,线程不会等待RPC的响应结果
等待-通知机制,在dubbo之间RPC发起调用时,线程进入Timed_WAITING状态,阻塞调用线程;当rpc返回结果后,唤醒等待线程
// 创建锁与条件变量
private final Lock lock=new ReentrantLock();
private final Condition done=lock.newCondition();
// 调用方通过该方法等待结果
Object get(int timeout){
long start=System.nanoTime();
lock.lock();
try{
while(!isDone()){
done.await(timeout);
long cur=System.nanoTime();
if(isDone()||
cur-start>timeout){
break;
}
}
}finally{
lock.unlock();
}
if(!isDone()){
throw new TimeoutException();
}
return returnFromResponse();
}
// RPC结果是否已经返回
boolean isDone(){
return response!=null;
}
// RPC结果返回时调用该方法
private void doReceived(Response res){
lock.lock();
try{
response=res;
if(done!=null){
done.signal();
}
}finally{
lock.unlock();
}
}