1.1. ShardingSphere
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。

1.1.1. 简介
ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

ShardingSphere-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。

ShardingSphere-Sidecar(TODO)
定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据库网格。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅 Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
混合架构
ShardingSphere-JDBC 采用无中心化架构,适用于 Java 开发的高性能的轻量级 OLTP 应用;ShardingSphere-Proxy 提供静态入口以及异构语言的支持,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景。
Apache ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 ShardingSphere-JDBC 和 ShardingSphere-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,使得架构师更加自由地调整适合与当前业务的最佳系统架构。

1.1.2. 功能列表
数据分片
背景
传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
在传统的关系型数据库无法满足互联网场景需要的情况下,将数据存储至原生支持分布式的 NoSQL 的尝试越来越多。 但 NoSQL 对 SQL 的不兼容性以及生态圈的不完善,使得它们在与关系型数据库的博弈中始终无法完成致命一击,而关系型数据库的地位却依然不可撼动。
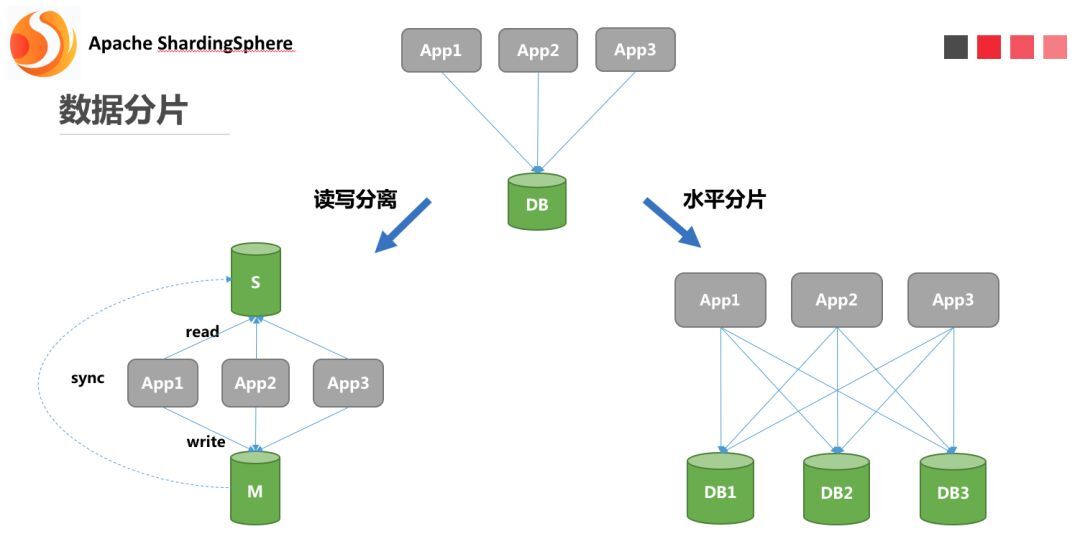
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
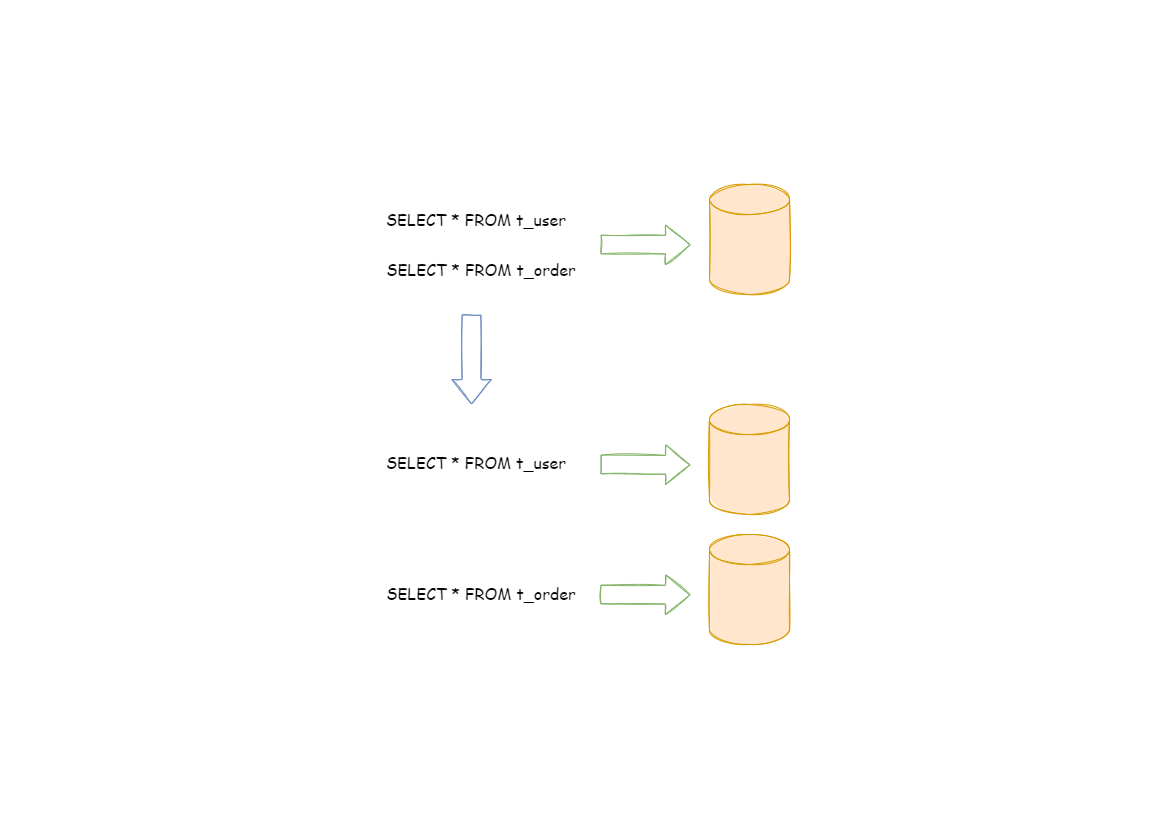
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
水平分片
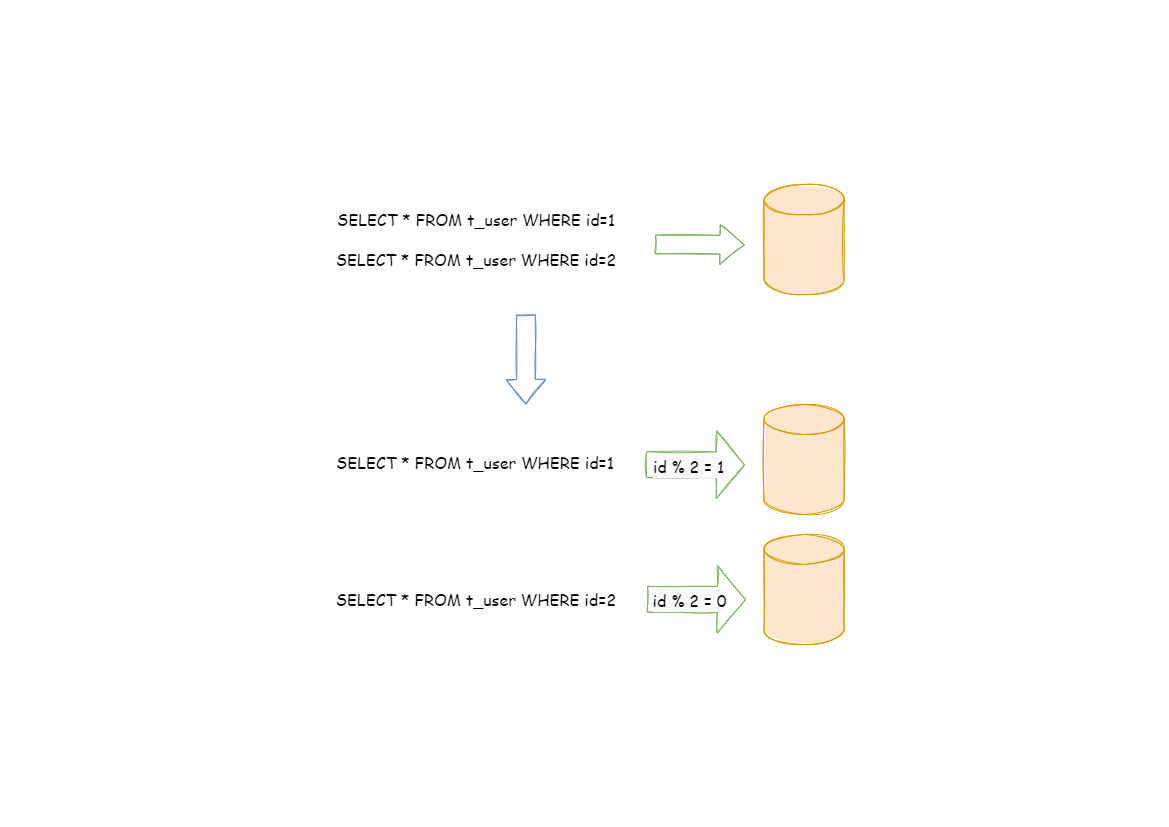
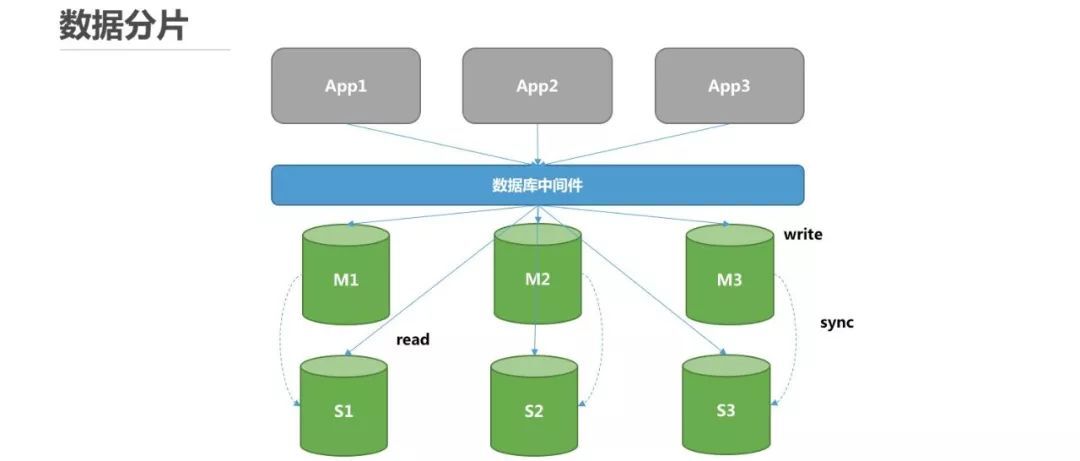
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
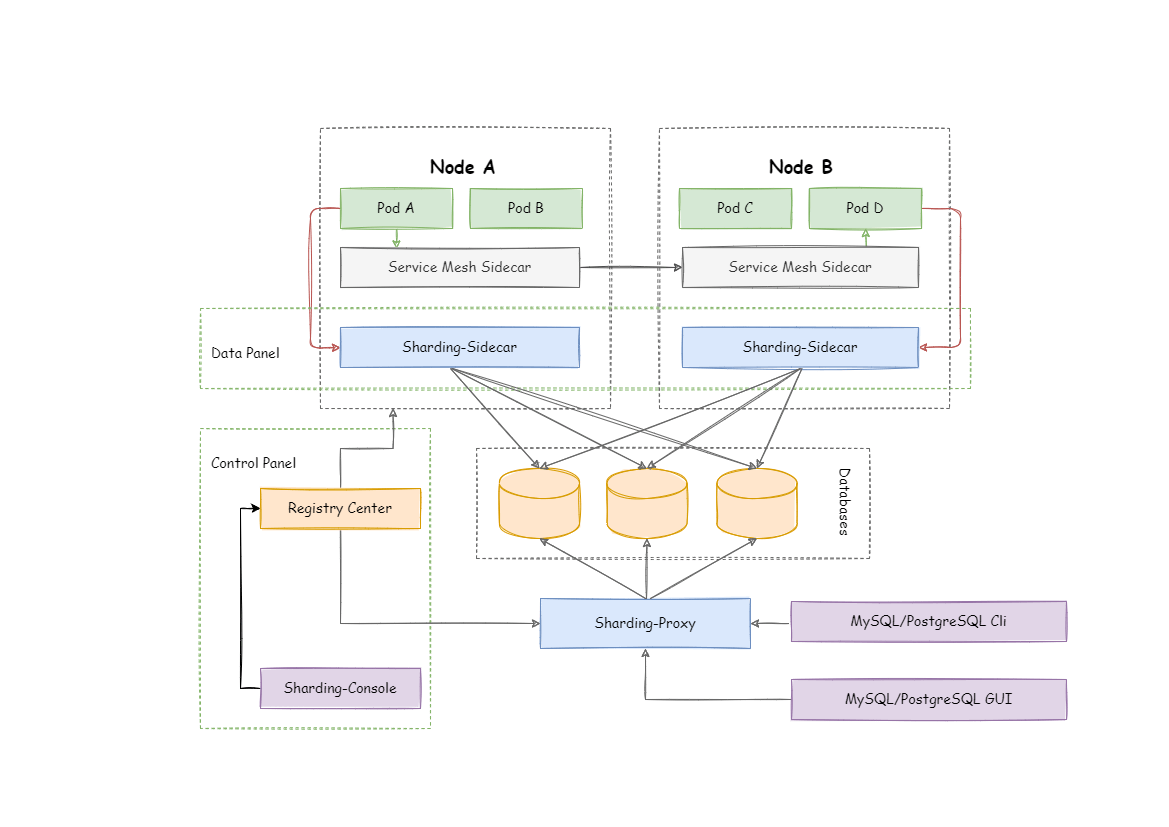
分片架构
数据分片
核心概念
SQL
逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的 t_order_0 到 t_order_9
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0
绑定表
指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果
SQL 为:
SELECT i.*
FROM t_order o
JOIN t_order_item i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.*
FROM t_order_0 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
SELECT i.*
FROM t_order_0 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
SELECT i.*
FROM t_order_1 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
SELECT i.*
FROM t_order_1 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.*
FROM t_order_0 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
SELECT i.*
FROM t_order_1 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE o.order_id in (10, 11);
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order
的条件。故绑定表之间的分区键要完全相同。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
分片
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL 中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过 =、>=、<=、>、<、BETWEEN 和 IN 分片。 分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。 由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 标准分片算法
对应 StandardShardingAlgorithm,用于处理使用单一键作为分片键的 =、IN、BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合
StandardShardingStrategy 使用。
- 复合分片算法
对应 ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合 ComplexShardingStrategy 使用。
- Hint分片算法
对应 HintShardingAlgorithm,用于处理使用 Hint 行分片的场景。需要配合 HintShardingStrategy 使用。
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供 5 种分片策略。
- 标准分片策略
对应 StandardShardingStrategy。提供对 SQ L语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。
StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。 PreciseShardingAlgorithm
是必选的,用于处理 = 和 IN 的分片。 RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND, >, <, >=, <=分片,如果不配置
RangeShardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。
- 复合分片策略
对应 ComplexShardingStrategy。复合分片策略。提供对 SQL 语句中的 =, >, <, >=, <=, IN 和 BETWEEN AND 的分片操作支持。
ComplexShardingStrategy 支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
- Hint分片策略
对应 HintShardingStrategy。通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略。
- 不分片策略
对应 NoneShardingStrategy。不分片的策略。
SQLHint
对于分片字段非 SQL 决定,而由其他外置条件决定的场景,可使用 SQL Hint 灵活的注入分片字段。 例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。 详情请参见强制分片路由
配置
分片规则
分片规则配置的总入口。包含数据源配置、表配置、绑定表配置以及读写分离配置等。
数据源配置
真实数据源列表。
表配置
逻辑表名称、数据节点与分表规则的配置。
数据节点配置
用于配置逻辑表与真实表的映射关系。可分为均匀分布和自定义分布两种形式。
- 均匀分布
指数据表在每个数据源内呈现均匀分布的态势,例如:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
那么数据节点配置如下:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
- 自定义分布
指数据表呈现有特定规则的分布,例如:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
那么数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度。
- 数据源分片策略
对应于 DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
- 表分片策略
对应于 TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
两种策略的 API 完全相同。
自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。
行表达式
语法说明
行表达式的使用非常直观,只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。 目前支持数据节点和分片算法这两个部分的配置。行表达式的内容使用的是 Groovy
的语法,Groovy 能够支持的所有操作,行表达式均能够支持。例如:
${begin..end} 表示范围区间
${[unit1, unit2, unit_x]} 表示枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
例如,以下行表达式:
${['online', 'offline']}_table${1..3}
配置数据节点
对于均匀分布的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
用行表达式可以简化为:
db${0..1}.t_order${0..1}
或者
db$->{0..1}.t_order$->{0..1}
对于自定义的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
用行表达式可以简化为:
db0.t_order${0..1},db1.t_order${2..4}
或者
db0.t_order$->{0..1},db1.t_order$->{2..4}
对于有前缀的数据节点,也可以通过行表达式灵活配置,如果数据结构如下:
db0
├── t_order_00
├── t_order_01
├── t_order_02
├── t_order_03
├── t_order_04
├── t_order_05
├── t_order_06
├── t_order_07
├── t_order_08
├── t_order_09
├── t_order_10
├── t_order_11
├── t_order_12
├── t_order_13
├── t_order_14
├── t_order_15
├── t_order_16
├── t_order_17
├── t_order_18
├── t_order_19
└── t_order_20
db1
├── t_order_00
├── t_order_01
├── t_order_02
├── t_order_03
├── t_order_04
├── t_order_05
├── t_order_06
├── t_order_07
├── t_order_08
├── t_order_09
├── t_order_10
├── t_order_11
├── t_order_12
├── t_order_13
├── t_order_14
├── t_order_15
├── t_order_16
├── t_order_17
├── t_order_18
├── t_order_19
└── t_order_20
可以使用分开配置的方式,先配置包含前缀的数据节点,再配置不含前缀的数据节点,再利用行表达式笛卡尔积的特性,自动组合即可。 上面的示例,用行表达式可以简化为:
db${0..1}.t_order_0${0..9}, db${0..1}.t_order_${10..20}
或者
db$->{0..1}.t_order_0$->{0..9}, db$->{0..1}.t_order_$->{10..20}
配置分片算法
对于只有一个分片键的使用 = 和 IN 进行分片的 SQL,可以使用行表达式代替编码方式配置。
行表达式内部的表达式本质上是一段 Groovy 代码,可以根据分片键进行计算的方式,返回相应的真实数据源或真实表名称。
例如:分为 10 个库,尾数为 0 的路由到后缀为 0 的数据源, 尾数为 1 的路由到后缀为 1 的数据源,以此类推。用于表示分片算法的行表达式为:
ds${id % 10}
或者
ds$->{id % 10}
内核剖析
解析引擎
抽象语法树
解析过程分为词法解析和语法解析。 词法解析器用于将 SQL 拆解为不可再分的原子符号,称为 Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将 词法解析器的输出 转换为抽象语法树。
例如,以下 SQL:
SELECT id, name
FROM t_user
WHERE status = 'ACTIVE'
AND age > 18
解析之后的为抽象语法树见下图。
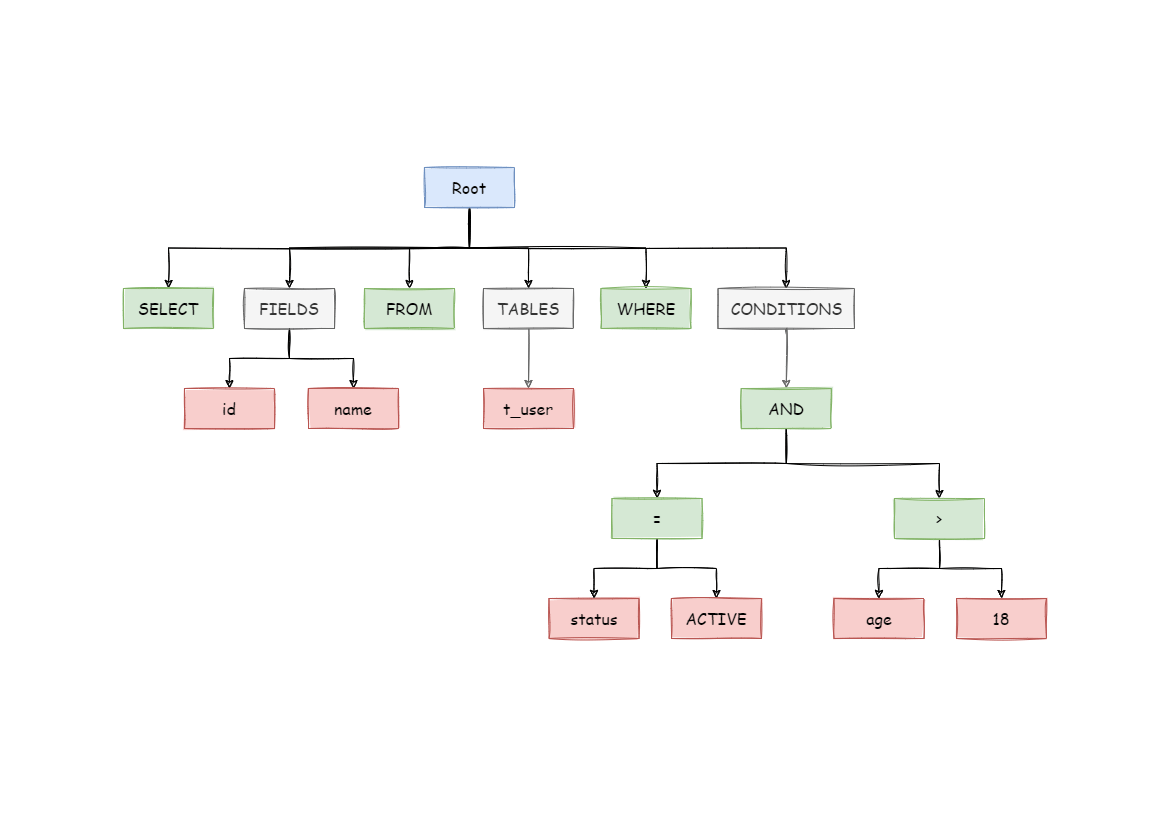
为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进一步拆分。
最后,通过visitor对抽象语法树遍历构造域模型,通过域模型(SQLStatement)去提炼分片所需的上下文,并标记有可能需要改写的位置。 供分片使用的解析上下文包含查询选择项(Select
Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group
By)以及分页信息(Limit、Rownum、Top)。 SQL 的一次解析过程是不可逆的,一个个 Token 按 SQL 原本的顺序依次进行解析,性能很高。 考虑到各种数据库 SQL 方言的异同,在解析模块提供了各类数据库的 SQL
方言字典。
SQL 解析引擎
功能点
- 提供独立的SQL解析功能
- 可以非常方便的对语法规则进行扩充和修改(使用了
ANTLR) - 支持多种方言的SQL解析
API使用
# 引入maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-engine</artifactId>
<version>${project.version}</version>
</dependency>
// 根据需要引入指定方言的解析模块(以MySQL为例),可以添加所有支持的方言,也可以只添加使用到的
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-mysql</artifactId>
<version>${project.version}</version>
</dependency>
- 获取语法树
/**
* databaseType type:String 可能值 MySQL,Oracle,PostgreSQL,SQL92,SQLServer
* sql type:String 解析的SQL
* useCache type:boolean 是否使用缓存
* @return parse tree
*/
ParseTree tree=new SQLParserEngine(databaseType).parse(sql,useCache);
- 获取SQLStatement
/**
* databaseType type:String 可能值 MySQL,Oracle,PostgreSQL,SQL92,SQLServer
* useCache type:boolean 是否使用缓存
* @return SQLStatement
*/
ParseTree tree=new SQLParserEngine(databaseType).parse(sql,useCache);
SQLVisitorEngine sqlVisitorEngine=new SQLVisitorEngine(databaseType,"STATEMENT");
SQLStatement sqlStatement=sqlVisitorEngine.visit(tree);
- SQL格式化
/**
* databaseType type:String 可能值 MySQL
* useCache type:boolean 是否使用缓存
* @return String
*/
ParseTree tree=new SQLParserEngine(databaseType).parse(sql,useCache);
SQLVisitorEngine sqlVisitorEngine=new SQLVisitorEngine(databaseType,"FORMAT");
String formatedSql=sqlVisitorEngine.visit(tree);
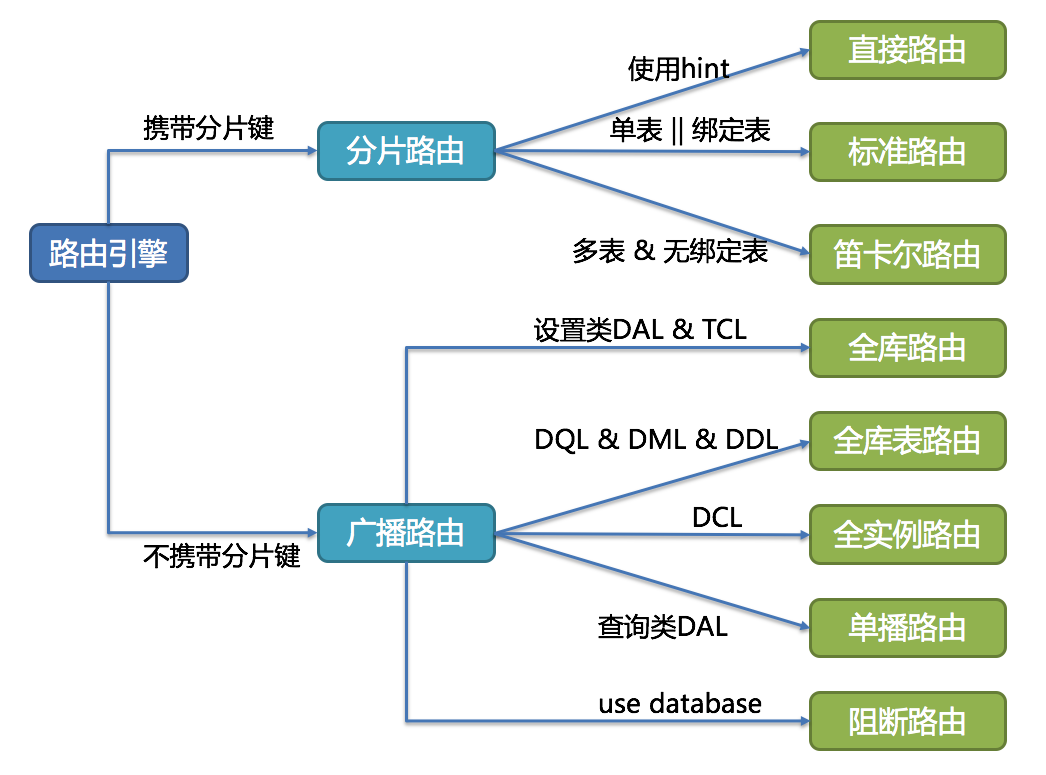
路由引擎
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的 SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是 IN)和范围路由(分片键的操作符是 BETWEEN)。 不携带分片键的 SQL 则采用广播路由。
分片路由
用于根据分片键进行路由的场景,又细分为直接路由、标准路由和笛卡尔积路由这 3 种类型
- 直接路由
满足直接路由的条件相对苛刻,它需要通过 Hint(使用 HintAPI 直接指定路由至库表)方式分片,并且是只分库不分表的前提下,则可以避免 SQL 解析和之后的结果归并。 因此它的兼容性最好,可以执行包括子查询、自定义函数等复杂情况的任意
SQL。直接路由还可以用于分片键不在 SQL 中的场景。例如,设置用于数据库分片的键为 3
hintManager.setDatabaseShardingValue(3);
假如路由算法为 value % 2,当一个逻辑库 t_order 对应 2 个真实库 t_order_0 和 t_order_1 时,路由后 SQL 将在 t_order_1 上执行。下方是使用 API 的代码样例:
String sql="SELECT * FROM t_order";
try(
HintManager hintManager=HintManager.getInstance();
Connection conn=dataSource.getConnection();
PreparedStatement pstmt=conn.prepareStatement(sql)){
hintManager.setDatabaseShardingValue(3);
try(ResultSet rs=pstmt.executeQuery()){
while(rs.next()){
//...
}
}
}
- 标准路由
标准路由是 ShardingSphere 最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的 SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是 BETWEEN 或 IN
时,则路由结果不一定落入唯一的库(表),因此一条逻辑 SQL 最终可能被拆分为多条用于执行的真实 SQL。 举例说明,如果按照 order_id 的奇数和偶数进行数据分片,一个单表查询的 SQL 如下:
SELECT*FROM t_order WHERE order_id IN(1,2);
那么路由的结果为:
SELECT *
FROM t_order_0
WHERE order_id IN (1, 2);
SELECT *
FROM t_order_1
WHERE order_id IN (1, 2);
绑定表的关联查询与单表查询复杂度和性能相当。举例说明,如果一个包含绑定表的关联查询的 SQL 如下:
SELECT *
FROM t_order_0 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
SELECT *
FROM t_order_1 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
- 笛卡尔路由
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。 如果上个示例中的 SQL 并未配置绑定表关系,那么路由的结果应为:
SELECT *
FROM t_order_0 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
SELECT *
FROM t_order_0 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
SELECT *
FROM t_order_1 o
JOIN t_order_item_0 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
SELECT *
FROM t_order_1 o
JOIN t_order_item_1 i ON o.order_id = i.order_id
WHERE order_id IN (1, 2);
广播路由
对于不携带分片键的 SQL,则采取广播路由的方式。根据 SQL 类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这 5 种类型。
- 全库表路由
全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的 DQL 和 DML,以及 DDL 等。例如:
SELECT *
FROM t_order
WHERE good_prority IN (1, 10);
则会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为
SELECT *
FROM t_order_0
WHERE good_prority IN (1, 10);
SELECT *
FROM t_order_1
WHERE good_prority IN (1, 10);
SELECT *
FROM t_order_2
WHERE good_prority IN (1, 10);
SELECT *
FROM t_order_3
WHERE good_prority IN (1, 10);
- 全库路由
全库路由用于处理对数据库的操作,包括用于库设置的 SET 类型的数据库管理命令,以及 TCL 这样的事务控制语句。 在这种情况下,会根据逻辑库的名字遍历所有符合名字匹配的真实库,并在真实库中执行该命令,例如
SET
autocommit=0;
在 t_order 中执行,t_order 有 2 个真实库。则实际会在 t_order_0 和 t_order_1 上都执行这个命令
- 全实例路由
全实例路由用于 DCL 操作,授权语句针对的是数据库的实例。无论一个实例中包含多少个 Schema,每个数据库的实例只执行一次。例如:
CREATE
USER customer@127.0.0.1 identified BY '123';
这个命令将在所有的真实数据库实例中执行,以确保 customer 用户可以访问每一个实例。
- 单波路由
单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。例如:
DESCRIBE t_order;
t_order 的两个真实表 t_order_0,t_order_1 的描述结构相同,所以这个命令在任意真实表上选择执行一次。
- 阻断路由
阻断路由用于屏蔽 SQL 对数据库的操作,例如:
USE
order_db;
这个命令不会在真实数据库中执行,因为 ShardingSphere 采用的是逻辑 Schema 的方式,无需将切换数据库 Schema 的命令发送至数据库中。
路由引擎的整体结构划分如下图。
分布式事务
数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。
- 原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行。
- 一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态。
- 隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性(Durability)指已提交的事务修改数据会被持久保存。
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
关系型数据库虽然对本地事务提供了完美的 ACID 原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。如何让数据库在分布式场景下满足 ACID 的特性或找寻相应的替代方案,是分布式事务的重点工作。
本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务。 它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
两阶段提交
XA协议最早的分布式事务模型是由 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing (DTP) 模型,简称 XA 协议。
基于XA协议实现的分布式事务对业务侵入很小。 它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。 XA协议能够严格保障事务 ACID 特性。
严格保障事务 ACID 特性是一把双刃剑。 事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。
因此,在高并发的性能至上场景中,基于XA协议的分布式事务并不是最佳选择。
柔性事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线。
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉。
- 而最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于 ACID 的强一致性事务和基于 BASE 的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。
| 本地事务 | 两(三)阶段事务 | 柔性事务 | |
|---|---|---|---|
| 业务改造 | 无 | 无 | 实现相关接口 |
| 一致性 | 不支持 | 支持 | 最终一致 |
| 隔离性 | 不支持 | 支持 | 业务方保证 |
| 并发性能 | 无影响 | 严重衰退 | 略微衰退 |
| 适合场景 | 业务方处理不一致 | 短事务 & 低并发 | 长事务 & 高并发 |
核心概念
XA两阶段事务
两阶段事务提交采用的是 X/OPEN 组织所定义的DTP模型所抽象的 AP(应用程序), TM(事务管理器)和
RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交。 TM
可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。

Java 通过定义 JTA 接口实现了 XA 模型,JTA 接口中的 ResourceManager 需要数据库厂商提供 XA 驱动实现, TransactionManager
则需要事务管理器的厂商实现,传统的事务管理器需要同应用服务器绑定,因此使用的成本很高。 而嵌入式的事务管器可以以 jar 包的形式提供服务,同 Apache ShardingSphere 集成后,可保证分片后跨库事务强一致性。
通常,只有使用了事务管理器厂商所提供的 XA 事务连接池,才能支持 XA 的事务。Apache ShardingSphere 在整合 XA 事务时,采用分离 XA 事务管理和连接池管理的方式,做到对应用程序的零侵入。
SEATA 柔性事务
Seata是阿里集团和蚂蚁金服联合打造的分布式事务框架。 其 AT 事务的目标是在微服务架构下,提供增量的事务 ACID 语意,让开发者像使用本地事务一样,使用分布式事务,核心理念同 Apache ShardingSphere 一脉相承。
Seata AT 事务模型包含TM (事务管理器),RM (资源管理器) 和 TC (事务协调器)。 TC 是一个独立部署的服务,TM 和 RM 以 jar 包的方式同业务应用一同部署,它们同 TC 建立长连接,在整个事务生命周期内,保持远程通信。 TM 是全局事务的发起方,负责全局事务的开启,提交和回滚。 RM 是全局事务的参与者,负责分支事务的执行结果上报,并且通过 TC 的协调进行分支事务的提交和回滚。
Seata 管理的分布式事务的典型生命周期:
- TM 要求 TC 开始一个全新的全局事务。TC 生成一个代表该全局事务的 XID。
- XID 贯穿于微服务的整个调用链。
- 作为该 XID 对应到的 TC 下的全局事务的一部分,RM 注册本地事务。
- TM 要求 TC 提交或回滚 XID 对应的全局事务。
- TC 驱动 XID 对应的全局事务下的所有分支事务完成提交或回滚。
![]()
实现原理
XA两阶段事务
XAShardingTransactionManager 为Apache ShardingSphere 的分布式事务的XA实现类。 它主要负责对多数据源进行管理和适配,并且将相应事务的开启、提交和回滚操作委托给具体的 XA 事务管理器。
![]()
开启全局事务
收到接入端的 set autoCommit=0 时,XAShardingTransactionManager 将调用具体的 XA 事务管理器开启 XA 全局事务,以 XID 的形式进行标记。
执行真实分片SQL
XAShardingTransactionManager将数据库连接所对应的 XAResource 注册到当前 XA 事务中之后,事务管理器会在此阶段发送 XAResource.start 命令至数据库。
数据库在收到 XAResource.end 命令之前的所有 SQL 操作,会被标记为 XA 事务。
XAResource1.start ## Enlist阶段执行
statement.execute("sql1"); ## 模拟执行一个分片SQL1
statement.execute("sql2"); ## 模拟执行一个分片SQL2
XAResource1.end ## 提交阶段执行
提交或回滚事务
XAShardingTransactionManager 在接收到接入端的提交命令后,会委托实际的 XA 事务管理进行提交动作, 事务管理器将收集到的当前线程中所有注册的 XAResource,并发送 XAResource.end
指令,用以标记此 XA 事务边界。 接着会依次发送 prepare 指令,收集所有参与 XAResource 投票。 若所有 XAResource 的反馈结果均为正确,则调用 commit 指令进行最终提交; 若有任意
XAResource 的反馈结果不正确,则调用 rollback 指令进行回滚。 在事务管理器发出提交指令后,任何 XAResource 产生的异常都会通过恢复日志进行重试,以保证提交阶段的操作原子性,和数据强一致性。
XAResource1.prepare ## ack: yes
XAResource2.prepare ## ack: yes
XAResource1.commit
XAResource2.commit
XAResource1.prepare ## ack: yes
XAResource2.prepare ## ack: no
XAResource1.rollback
XAResource2.rollback
Seata 柔性事务
整合 Seata AT 事务时,需要将 TM,RM 和 TC 的模型融入 Apache ShardingSphere 的分布式事务生态中。 在数据库资源上,Seata 通过对接 DataSource 接口,让 JDBC 操作可以同 TC
进行远程通信。 同样,Apache ShardingSphere 也是面向 DataSource 接口,对用户配置的数据源进行聚合。 因此,将 DataSource 封装为 基于Seata 的 DataSource 后,就可以将
Seata AT 事务融入到 Apache ShardingSphere的分片生态中。
![]()
引擎初始化
包含 Seata 柔性事务的应用启动时,用户配置的数据源会根据 seata.conf 的配置,适配为 Seata 事务所需的 DataSourceProxy,并且注册至 RM 中。
开启全局事务
TM 控制全局事务的边界,TM 通过向 TC 发送 Begin 指令,获取全局事务 ID,所有分支事务通过此全局事务 ID,参与到全局事务中;全局事务 ID 的上下文存放在当前线程变量中。
执行真实分片SQL
处于 Seata 全局事务中的分片 SQL 通过 RM 生成 undo 快照,并且发送 participate 指令至 TC,加入到全局事务中。 由于 Apache ShardingSphere 的分片物理 SQL
采取多线程方式执行,因此整合 Seata AT 事务时,需要在主线程和子线程间进行全局事务 ID 的上下文传递。
提交或回滚事务
提交 Seata 事务时,TM 会向 TC 发送全局事务的提交或回滚指令,TC 根据全局事务 ID 协调所有分支事务进行提交或回滚。
分布式治理
治理
配置中心
配置中心数据结构
配置中心在定义的命名空间下,以 YAML 格式存储,包括数据源信息,规则信息、权限配置和属性配置,可通过修改节点来实现对于配置的动态管理。
namespace
├──authentication # 权限配置
├──props # 属性配置
├──schemas # Schema 配置
├ ├──${schema_1} # Schema 名称1
├ ├ ├──datasource # 数据源配置
├ ├ ├──rule # 规则配置
├ ├ ├──table # 表结构配置
├ ├──${schema_2} # Schema 名称2
├ ├ ├──datasource # 数据源配置
├ ├ ├──rule # 规则配置
├ ├ ├──table # 表结构配置
/authentication
权限配置,可配置访问 ShardingSphere-Proxy 的用户名和密码
username: root
password: root
/props
属性配置,详情请参见配置手册。
executor-size: 20
sql-show: true
/schemas/${schemeName}/datasource
多个数据库连接池的集合,不同数据库连接池属性自适配(例如:DBCP,C3P0,Druid, HikariCP)。
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
props:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
password: null
maxPoolSize: 50
maintenanceIntervalMilliseconds: 30000
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
minPoolSize: 1
username: root
maxLifetimeMilliseconds: 1800000
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
props:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
password: null
maxPoolSize: 50
maintenanceIntervalMilliseconds: 30000
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
minPoolSize: 1
username: root
maxLifetimeMilliseconds: 1800000
/schemas/${schemeName}/rule
规则配置,可包括数据分片、读写分离、数据加密、影子库压测等配置。
rules:
- !SHARDING
xxx
- !REPLICA_QUERY
xxx
- !ENCRYPT
xxx
/schemas/${schemeName}/table
表结构配置,暂不支持动态修改。
tables: # 表
t_order: # 表名
columns: # 列
id: # 列名
caseSensitive: false
dataType: 0
generated: false
name: id
primaryKey: trues
order_id:
caseSensitive: false
dataType: 0
generated: false
name: order_id
primaryKey: false
indexs: # 索引
t_user_order_id_index: # 索引名
name: t_user_order_id_index
t_order_item:
columns:
order_id:
caseSensitive: false
dataType: 0
generated: false
name: order_id
primaryKey: false
注册中心
注册中心数据结构
注册中心在定义的命名空间的 states 节点下,创建数据库访问对象运行节点,用于区分不同数据库访问实例。包括 proxynodes 和 datanodes 节点。
namespace
├──states
├ ├──proxynodes
├ ├ ├──${your_instance_ip_a}@${your_instance_pid_x}@${UUID}
├ ├ ├──${your_instance_ip_b}@${your_instance_pid_y}@${UUID}
├ ├ ├──....
├ ├──datanodes
├ ├ ├──${schema_1}
├ ├ ├ ├──${ds_0}
├ ├ ├ ├──${ds_1}
├ ├ ├──${schema_2}
├ ├ ├ ├──${ds_0}
├ ├ ├ ├──${ds_1}
├ ├ ├──....
/states/proxynodes
数据库访问对象运行实例信息,子节点是当前运行实例的标识。 运行实例标识由运行服务器的 IP 地址和 PID 构成。运行实例标识均为临时节点,当实例上线时注册,下线时自动清理。 注册中心监控这些节点的变化来治理运行中实例对数据库的访问等。
/states/datanodes
可以治理读写分离从库,可动态添加删除以及禁用。
1.1.3. 安装使用
ShardingSphere-JDBC
引入maven依赖
# latest.release.version换成指定版本
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
配置说明(yaml)
# 数据分片
dataSources: # 省略数据源配置
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考Inline语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: #分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table-name>
- <table-name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
# 分片算法配置
shardingAlgorithms:
<sharding-algorithm-name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key-generate-algorithm-name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
props:
# ...
# 读写分离
dataSources: # 省略数据源配置
rules:
- !REPLICA_QUERY
dataSources:
<data-source-name> (+): # 读写分离逻辑数据源名称
primaryDataSourceName: # 主库数据源名称
replicaDataSourceNames:
- <replica-data_source-name> (+) # 从库数据源名称
loadBalancerName: # 负载均衡算法名称
# 负载均衡算法配置
loadBalancers:
<load-balancer-name> (+): # 负载均衡算法名称
type: # 负载均衡算法类型
props: # 负载均衡算法属性配置
# ...
props:
# ...
# 数据加密
dataSource: # 省略数据源配置
rules:
- !ENCRYPT
tables:
<table-name> (+): # 加密表名称
columns:
<column-name> (+): # 加密列名称
cipherColumn: # 密文列名称
assistedQueryColumn (?): # 查询辅助列名称
plainColumn (?): # 原文列名称
encryptorName: # 加密算法名称
# 加密算法配置
encryptors:
<encrypt-algorithm-name> (+): # 加解密算法名称
type: # 加解密算法类型
props: # 加解密算法属性配置
# ...
props:
# ...
# 影子库
dataSources: #省略数据源配置
rules:
- !SHADOW
column: # 影子字段名
sourceDataSourceNames: # 影子前数据库名
# ...
shadowDataSourceNames: # 对应的影子库名
# ...
props:
# ...
# 分布式治理
governance:
name: # 治理名称
registryCenter: # 配置中心
type: # 治理持久化类型。如:Zookeeper, etcd
serverLists: # 治理服务列表。包括 IP 地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
additionalConfigCenter:
type: # 治理持久化类型。如:Zookeeper, etcd, Nacos, Apollo
serverLists: # 治理服务列表。包括 IP 地址和端口号。多个地址用逗号分隔。如: host1:2181,host2:2181
overwrite: # 本地配置是否覆盖配置中心配置。如果可覆盖,每次启动都以本地配置为准
规则配置
ShardingSphere-JDBC 的 YAML 配置文件 通过数据源集合、规则集合以及属性配置组成。 以下示例是根据 user_id 取模分库, 且根据 order_id 取模分表的 2 库 2 表的配置。
# 配置真实数据源
dataSources:
# 配置第 1 个数据源
ds0: !!org.apache.commons.dbcp2.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password:
# 配置第 2 个数据源
ds1: !!org.apache.commons.dbcp2.BasicDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password:
rules:
# 配置分片规则
- !SHARDING
tables:
# 配置 t_order 表规则
t_order:
actualDataNodes: ds${0..1}.t_order${0..1}
# 配置分库策略
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
# 配置分表策略
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
t_order_item:
# 省略配置 t_order_item 表规则...
# ...
# 配置分片算法
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds${user_id % 2}
table_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
安装
下载地址:https://archive.apache.org/dist/shardingsphere/
# 下载
wget https://archive.apache.org/dist/shardingsphere/4.1.1/apache-shardingsphere-4.1.1-sharding-jdbc-bin.tar.gz -P /usr/local/src
通过 YamlGovernanceShardingSphereDataSourceFactory 工厂创建的 GovernanceShardingSphereDataSource 实现自 JDBC 的标准接口 DataSource。
// 指定 YAML 文件路径
File yamlFile= // ...
// 创建 ShardingSphereDataSource
DataSource dataSource=YamlShardingSphereDataSourceFactory.createDataSource(yamlFile);
使用 ShardingSphereDataSource
通过 YamlShardingSphereDataSourceFactory 工厂创建的 ShardingSphereDataSource 实现自 JDBC 的标准接口 DataSource。 可通过 DataSource 选择使用原生 JDBC,或JPA, MyBatis 等 ORM 框架。
DataSource dataSource=YamlShardingSphereDataSourceFactory.createDataSource(yamlFile);
String sql="SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=? AND o.order_id=?";
try(
Connection conn=dataSource.getConnection();
PreparedStatement ps=conn.prepareStatement(sql)){
ps.setInt(1,10);
ps.setInt(2,1000);
try(ResultSet rs=preparedStatement.executeQuery()){
while(rs.next()){
// ...
}
}
}
Shardingsphere-Proxy
配置说明
# 数据源配置
schemaName: # 逻辑数据源名称
dataSources: # 数据源配置,可配置多个 <data-source-name>
<data-source-name>: # 与 ShardingSphere-JDBC 配置不同,无需配置数据库连接池
url: #数据库 URL 连接
username: # 数据库用户名
password: # 数据库密码
connectionTimeoutMilliseconds: # 连接超时毫秒数
idleTimeoutMilliseconds: # 空闲连接回收超时毫秒数
maxLifetimeMilliseconds: # 连接最大存活时间毫秒数
maxPoolSize: 50 # 最大连接数
minPoolSize: 1 # 最小连接数
rules: # 与 ShardingSphere-JDBC 配置一致
# ...
# 权限配置
authentication:
users:
root: # 自定义用户名
password: root # 自定义用户名
sharding: # 自定义用户名
password: sharding # 自定义用户名
authorizedSchemas: sharding_db, replica_query_db # 该用户授权可访问的数据库,多个用逗号分隔。缺省将拥有 root 权限,可访问全部数据库。
# 属性配置
配置规则
schemaName: # 逻辑数据源名称
dataSources: # 数据源配置,可配置多个 <data-source-name>
<data-source-name>: # 与 ShardingSphere-JDBC 配置不同,无需配置数据库连接池
url: #数据库 URL 连接
username: # 数据库用户名
password: # 数据库密码
connectionTimeoutMilliseconds: # 连接超时毫秒数
idleTimeoutMilliseconds: # 空闲连接回收超时毫秒数
maxLifetimeMilliseconds: # 连接最大存活时间毫秒数
maxPoolSize: 50 # 最大连接数
minPoolSize: 1 # 最小连接数
rules: # 与 ShardingSphere-JDBC 配置一致
# ...
authentication:
users:
root: # 自定义用户名
password: root # 自定义用户名
sharding: # 自定义用户名
password: sharding # 自定义用户名
authorizedSchemas: sharding_db, replica_query_db # 该用户授权可访问的数据库,多个用逗号分隔。缺省将拥有 root 权限,可访问全部数据库。
安装
- 二进制安装
# 下载
wget https://archive.apache.org/dist/shardingsphere/4.1.1/apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz -P /usr/local/src
# 创建配置
## 分片
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
## 主从
schemaName: master_slave_db
dataSources:
master_ds:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_master?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_slave_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1
## 加密
schemaName: encrypt_db
dataSource:
url: jdbc:mysql://127.0.0.1:3306/demo_ds?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
encryptRule:
encryptors:
encryptor_aes:
type: aes
props:
aes.key.value: 123456abc
encryptor_md5:
type: md5
tables:
t_encrypt:
columns:
user_id:
plainColumn: user_plain
cipherColumn: user_cipher
encryptor: encryptor_aes
order_id:
cipherColumn: order_cipher
encryptor: encryptor_md5
# 拷贝mysql驱动包
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.23/mysql-connector-java-8.0.23.jar -P /${work_dir}/ext-lib
# 配置
cat > /${work_dir}/conf/server.yaml <<- 'EOF'
#orchestration:
# orchestration_ds:
# orchestrationType: registry_center,config_center,distributed_lock_manager
# instanceType: zookeeper
# serverLists: localhost:2181
# namespace: orchestration
# props:
# overwrite: false
# retryIntervalMilliseconds: 500
# timeToLiveSeconds: 60
# maxRetries: 3
# operationTimeoutMilliseconds: 500
#
authentication:
users:
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
max.connections.size.per.query: 1
acceptor.size: 16 # The default value is available processors count * 2.
executor.size: 16 # Infinite by default.
proxy.frontend.flush.threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy.transaction.type: LOCAL
proxy.opentracing.enabled: false
proxy.hint.enabled: false
query.with.cipher.column: true
sql.show: false
allow.range.query.with.inline.sharding: false
EOF
cat > /${work_dir}/conf/config-sharding.yaml <<- 'EOF'
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.tbl${0..1}
tableStrategy:
inline:
shardingColumn: k
algorithmExpression: tbl_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: id
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
EOF
# 命令行启动
./bin/start.sh
# 创建账号
groupadd shardingproxy
useradd shardingproxy -g shardingproxy -s /sbin/nologin
# 配置systemd启动
cat > /usr/lib/systemd/system/shardingproxy.service <<- 'EOF'
[Unit]
Description=shardingproxy
After=network.target
[Service]
User=shardingproxy
Group=shardingproxy
TimeoutStartSec=30
ExecStart=/usr/local/bin/start.sh
ExecStop=/bin/kill $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动shardingsphere
systemctl enable shardingproxy
systemctl enable shardingproxy
# 配置接入skywalking
skywalking_agent="-Dskywalking.agent.service_name=${SKYWALKING_SERVICE_NAME}
-Dskywalking.agent.instance_name=$(ip a |grep eth0|grep inet|awk '{print $2}'|awk -F / '{print $1}') -javaagent:/opt/skywalking/agent/skywalking-agent.jar"
PROJECT_OPTS="${JAVA_OPTS} -Djava.security.egd=file:/dev/./urandom -jar"
java $JAVA_OPTS $skywalking_agent $PROJECT_OPTS -jar /apps/app.jar
- docker 安装
# 拉取镜像
docker pull apache/shardingsphere-proxy:4.1.1
# 手动构建
git clone https://github.com/apache/shardingsphere
mvn clean install
cd shardingsphere-distribution/shardingsphere-proxy-distribution
mvn clean package -Prelease,docker
# 配置
cat > conf/server.yaml <<- 'EOF'
#orchestration:
# orchestration_ds:
# orchestrationType: registry_center,config_center,distributed_lock_manager
# instanceType: zookeeper
# serverLists: localhost:2181
# namespace: orchestration
# props:
# overwrite: false
# retryIntervalMilliseconds: 500
# timeToLiveSeconds: 60
# maxRetries: 3
# operationTimeoutMilliseconds: 500
#
authentication:
users:
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
max.connections.size.per.query: 1
acceptor.size: 16 # The default value is available processors count * 2.
executor.size: 16 # Infinite by default.
proxy.frontend.flush.threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy.transaction.type: LOCAL
proxy.opentracing.enabled: false
proxy.hint.enabled: false
query.with.cipher.column: true
sql.show: false
allow.range.query.with.inline.sharding: false
EOF
cat > conf/config-sharding.yaml <<- 'EOF'
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_0?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
defaultTableStrategy:
none:
EOF
cat > conf/logback.xml <<- 'EOF'
<?xml version="1.0"?>
<!--
~ Licensed to the Apache Software Foundation (ASF) under one or more
~ contributor license agreements. See the NOTICE file distributed with
~ this work for additional information regarding copyright ownership.
~ The ASF licenses this file to You under the Apache License, Version 2.0
~ (the "License"); you may not use this file except in compliance with
~ the License. You may obtain a copy of the License at
~
~ http://www.apache.org/licenses/LICENSE-2.0
~
~ Unless required by applicable law or agreed to in writing, software
~ distributed under the License is distributed on an "AS IS" BASIS,
~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
~ See the License for the specific language governing permissions and
~ limitations under the License.
-->
<configuration>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%-5level] %d{HH:mm:ss.SSS} [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="org.apache.shardingsphere" level="info" additivity="false">
<appender-ref ref="console"/>
</logger>
<root>
<level value="info" />
<appender-ref ref="console" />
</root>
</configuration>
EOF
# 拷贝mysql 驱动包
cp /usr/local/src/mysql-connector-java-8.0.23.jar ext-lib/
# 创建数据库
create database ds_0 default character set utf8mb4;
create database ds_1 default character set utf8mb4;
# 创建数据表
CREATE TABLE `tbl_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT 0,
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
CREATE TABLE `tbl_1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT 0,
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
CREATE TABLE `t_order_0` (
`order_id` int NOT NULL,
`user_id` int NOT NULL,
`status` varchar(45) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_order_1` (
`order_id` int NOT NULL,
`user_id` int NOT NULL,
`status` varchar(45) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_item_0` (
`item_id` int NOT NULL,
`order_id` int NOT NULL,
`user_id` int NOT NULL,
`status` varchar(45) DEFAULT NULL,
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_item_1` (
`item_id` int NOT NULL,
`order_id` int NOT NULL,
`user_id` int NOT NULL,
`status` varchar(45) DEFAULT NULL,
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# 运行docker
cd ${work_dir}/scripts
cat > start.sh <<- 'EOF'
#!/usr/bin/env bash
work_dir=`pwd`
docker stop sharding-proxy
docker rm sharding-proxy
docker run --name sharding-proxy \
-v /${work_dir}/conf:/opt/sharding-proxy/conf \
-v /${work_dir}/ext-lib:/opt/sharding-proxy/ext-lib \
-e PORT=3308 \
-e JWT_OPTS="-Djava.awt.headless=true" \
-p 13308:3308 \
-d apache/sharding-proxy:4.1.1
EOF
sh /${work_dir}/scripts/start.sh
- kubernetes 安装
# 创建dockerfile
# 生成helm chart
helm create shardingproxy
- 连接使用
mysql -h10.100.0.1 -P 13308 -usharding -psharding
1.1.4. 性能测试
测试场景
单路由
在1000数据量的基础上分库分表,根据id分为4个库,部署在同一台机器上,根据k分为1024个表,查询操作路由到单库单表;
作为对比,MySQL运行在1000数据量的基础上,使用INSERT+UPDATE+DELETE和单路由查询语句。
主从
基本主从场景,设置一主库一从库,部署在两台不同的机器上,在10000数据量的基础上,观察读写性能; 作为对比,MySQL运行在10000数据量的基础上,使用INSERT+SELECT+DELETE语句。
主从+加密+分库分表
在1000数据量的基础上,根据id分为4个库,部署在四台不同的机器上,根据k分为1024个表,c使用aes加密,pad使用md5加密,查询操作路由到单库单表;
作为对比,MySQL运行在1000数据量的基础上,使用INSERT+UPDATE+DELETE和单路由查询语句。
全路由
在1000数据量的基础上,分库分表,根据id分为4个库,部署在四台不同的机器上,根据k分为1个表,查询操作使用全路由。 作为对比,MySQL运行在1000数据量的基础上,使用INSERT+UPDATE+DELETE和全路由查询语句。
测试环境搭建
数据库表结构
CREATE TABLE `tbl`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT 0,
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
测试场景配置
单路由配置
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_1:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_2:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_3:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
rules:
- !SHARDING
tables:
tbl:
actualDataNodes: ds_${0..3}.tbl${0..1023}
tableStrategy:
standard:
shardingColumn: k
shardingAlgorithmName: tbl_table_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: default_db_inline
defaultTableStrategy:
none:
shardingAlgorithms:
tbl_table_inline:
type: INLINE
props:
algorithm-expression: tbl${k % 1024}
default_db_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 4}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
主从配置
schemaName: sharding_db
dataSources:
primary_ds:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
replica_ds_0:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
rules:
- !REPLICA_QUERY
dataSources:
pr_ds:
name: pr_ds
primaryDataSourceName: primary_ds
replicaDataSourceNames:
- replica_ds_0
主从+加密+分库分表配置
schemaName: sharding_db
dataSources:
primary_ds_0:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
replica_ds_0:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
primary_ds_1:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
replica_ds_1:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
primary_ds_2:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
replica_ds_2:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
primary_ds_3:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
replica_ds_3:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
rules:
- !SHARDING
tables:
tbl:
actualDataNodes: pr_ds_${0..3}.tbl${0..1023}
databaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: tbl_database_inline
tableStrategy:
standard:
shardingColumn: k
shardingAlgorithmName: tbl_table_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
bindingTables:
- tbl
defaultDataSourceName: primary_ds_1
defaultTableStrategy:
none:
shardingAlgorithms:
tbl_database_inline:
type: INLINE
props:
algorithm-expression: pr_ds_${id % 4}
tbl_table_inline:
type: INLINE
props:
algorithm-expression: tbl${k % 1024}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
- !REPLICA_QUERY
dataSources:
pr_ds_0:
primaryDataSourceName: primary_ds_0
replicaDataSourceNames:
- replica_ds_0
loadBalancerName: round_robin
pr_ds_1:
primaryDataSourceName: primary_ds_1
replicaDataSourceNames:
- replica_ds_1
loadBalancerName: round_robin
pr_ds_2:
primaryDataSourceName: primary_ds_2
replicaDataSourceNames:
- replica_ds_2
loadBalancerName: round_robin
pr_ds_3:
primaryDataSourceName: primary_ds_3
replicaDataSourceNames:
- replica_ds_3
loadBalancerName: round_robin
loadBalancers:
round_robin:
type: ROUND_ROBIN
- !ENCRYPT:
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
md5_encryptor:
type: MD5
tables:
sbtest:
columns:
c:
plainColumn: c_plain
cipherColumn: c_cipher
encryptorName: aes_encryptor
pad:
cipherColumn: pad_cipher
encryptorName: md5_encryptor
props:
query-with-cipher-column: true
全路由
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_1:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_2:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
ds_3:
url: jdbc:mysql://***.***.***.***:****/ds?serverTimezone=UTC&useSSL=false
username: test
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
rules:
- !SHARDING
tables:
tbl:
actualDataNodes: ds_${0..3}.tbl1
tableStrategy:
standard:
shardingColumn: k
shardingAlgorithmName: tbl_table_inline
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
defaultDatabaseStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: default_database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
default_database_inline:
type: INLINE
props:
algorithm-expression: ds_${id % 4}
tbl_table_inline:
type: INLINE
props:
algorithm-expression: tbl1
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
测试结果验证
压测语句
INSERT+UPDATE+DELETE语句:
INSERT INTO tbl(k, c, pad) VALUES(1, '###-###-###', '###-###');
UPDATE tbl SET c='####-####-####', pad='####-####' WHERE id=?;
DELETE FROM tbl WHERE id=?
全路由查询语句:
SELECT max(id) FROM tbl WHERE id%4=1
单路由查询语句:
SELECT id, k FROM tbl ignore index(`PRIMARY`) WHERE id=1 AND k=1
INSERT+SELECT+DELETE语句:
INSERT INTO tbl1(k, c, pad) VALUES(1, '###-###-###', '###-###');
SELECT count(id) FROM tbl1;
SELECT max(id) FROM tbl1 ignore index(`PRIMARY`);
DELETE FROM tbl1 WHERE id=?
压测执行
# 生成jar包
git clone https://github.com/apache/shardingsphere-benchmark.git
cd shardingsphere-benchmark/shardingsphere-benchmark
mvn clean install
# jmeter 压测
cp target/shardingsphere-benchmark-1.0-SNAPSHOT-jar-with-dependencies.jar apache-jmeter-4.0/lib/ext
jmeter –n –t test_plan/test.jmx
test.jmx参考https://github.com/apache/shardingsphere-benchmark/tree/master/report/script/test_plan/test.jmx
压测结果处理
sh shardingsphere-benchmark/report/script/gen_report.sh
1.1.5. 问题点
数据库未创建报错
Caused by: java.sql.SQLSyntaxErrorException: Unknown database 'ds_0'
# 解决办法,创建对应的数据库
create database ds_0 default character set utf8mb4;
create database ds_1 default character set utf8mb4;
需要手动创建库表
#
创建数据库
create
database ds_0 default character set utf8mb4;
create
database ds_1 default character set utf8mb4;
#
创建数据表
CREATE TABLE `tbl_0`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT 0,
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
CREATE TABLE `tbl_1`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT 0,
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);