1. ES
基于lucene的分布式搜索引擎
1.1. 分布式架构原理
- 创建的索引指定N个shard,支持横向扩展,提高性能;每个shard都有一个primary shard,负责写入数据,还有几个replica shard,primary shard写入数据后,会将数据同步到其它几个replica shard
- es集群多个节点,会自动选举一个节点为master节点,master节点负责维护索引元数据,切换primary shard和replica shard身份。要是master节点宕机,会重新选举一个节点为master
1.2. ES写入数据的流程
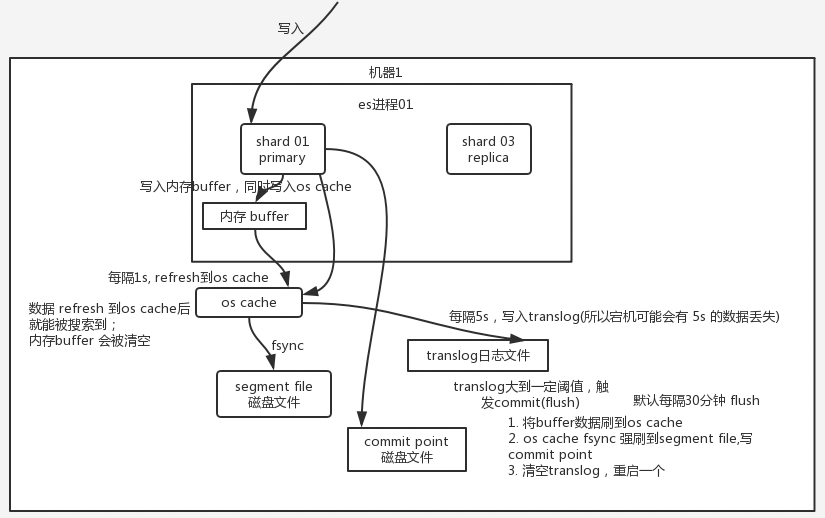
ES写入/查询流程
1.2.1. 写数据过程
- 客户端选择一个node发送请求过去,这个node是coordinating node(协调节点)
- ciirdinating node对document进行路由,将请求转发给对应的node(primary shard)
- 实际的node上primary shard处理请求,将数据同步到replica node
- coordinating node发现primary node和所有replica node都搞定后,返回响应结果给客户端
1.2.2. 读数据过程
- 通过doc id来查询,根据doc id进行hash,判断出来当时把doc id分配到哪个shard上去,从哪个shard去查询
- 客户端发送请求到任意一个node,成为coordinate node
- coordinate node对doc id进行哈希路由,请求转发到对应的node,使用round-robin随机轮询算法,在primary shard以及所有replica中随机选择一个,读请求负载均衡
- 接收请求的node返回document给coordinate node
- coordinate node返回document给客户端
1.2.3. es搜索数据过程
- 客户端发送请求到一个coordinate node
- 协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard
- query phase:每个shard将自己的搜索结果返回给协调节点(doc id),由协调节点进行数据合并、排序、分页等,产出最终结果
- fetch phase:由协调节点根据doc id去各个节点上拉去实际的document数据,返回客户端
1.2.4. 删除/更新数据底层原理
- 删除操作:commit会生成一个.del文件,将某个doc标识为deleted状态
- 更新操作:原来的doc标识为deleted状态,然后新写入一条数据
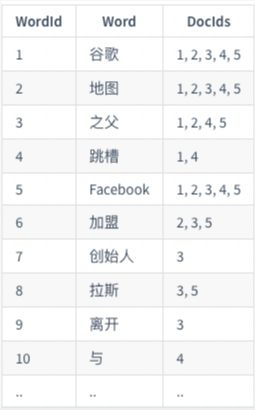
1.2.5. 倒排索引
正向索引是通过key找value,反向索引则是通过value找key
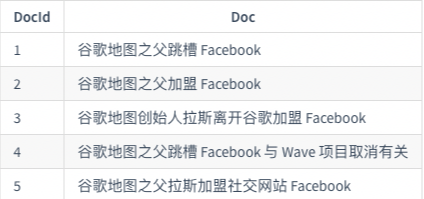
倒排索引如下:
1.3. 数十亿级别数据下如何提高查询效率
主要是filesystem cache,让机器内存,至少可以容纳总数据量的一半
比如现在一行数据,id,name,age...30个字段。但是现在搜索只需要根据id,name,age3个字段来搜索,如果在es里写入了一行数据所有字段,则导致90%的数据不是用来搜索的,就会占据fileasystem cache的内存。
解决使用es+hbase,hbase适用于海量数据在线存储,但不要做复杂的搜索